






ChatGPT als Hegemonieverstärker
Eine Gesellschaft mit unechten Menschen, die wir nicht von echten unterscheiden können, wird bald gar keine Gesellschaft mehr sein.1 (Emily Bender, Computerlinguistin)
Die Künstliche Intelligenz (KI) erlebt aktuell ihren iPhone-Moment. ChatGPT hat einen beispiellosen Hype um künstliche Intelligenz ausgelöst. Innerhalb von zwei Monaten haben mehr als 100 Millionen Menschen weltweit die neue Technik ausprobiert.
Sprachmodelle – keine Wissensmodelle
Der Chatbot2 ChatGPT basiert auf einem sogenannten großen Sprachmodell, das wir uns wie einen sehr großen Schaltkreis mit (im aktuellen Fall von GPT-4) einer Billion justierbarer Parameter vorstellen können. Ein Sprachmodell beginnt als unbeschriebenes Blatt und wird mit mehreren Billionen Wörtern Text trainiert. Die Funktionsweise eines solchen Modells ist, das nächste Wort in einer Folge von Wörtern aus dem ‚Erlernten‘ zu erraten. Die Bedeutung von Worten ist für ein Sprachmodell lediglich die statistische Erfassung des Kontexts, in dem sie auftauchen.
Dieses Imitieren von Text-‚Verständnis’ bzw. ‚Wissen‘ über die Berechnung von Wahrscheinlichkeiten für das Auftauchen einzelner Wörter innerhalb von komplexen Wortmustern klappt teilweise verblüffend gut. Das Generieren von Inhalt ohne jegliches semantisches Verständnis hat natürlich den Nachteil, dass auch sehr viel Unsinn (im engeren Sinn) produziert wird. ChatGPT erzeugt mit dieser Taktik der Nachahmung von Trainingstexten beispielsweise wissenschaftlich anmutende Abhandlungen, inklusive ‚frei erfundener‘ Referenzen, die strukturell stimmig aussehen, aber nicht existieren. ChatGPT ‚erfindet‘ Dinge und produziert dadurch massenweise Fake-Inhalte – das liegt daran, dass es sich um ein statistisches Sprachmodell und nicht um ein wissensbasiertes Modell handelt.
Es ist daher für ein Restmaß an ‚Faktizität‘ im Internet wenig förderlich, dass Google und Microsoft die neuesten Versionen ihrer Suchmaschinen mit den jeweiligen Sprachmodellen ChatGPT bzw. Bard koppeln. Denn eines kann Künstliche Intelligenz in Form von Sprachmodellen noch weniger als jede aggregierte themenbasierte Internetsuche: Fakten prüfen. Da Sprachmodelle lediglich Wahrscheinlichkeiten von für sie bedeutungslosen Sprachformen berechnen, ist ein Faktencheck neuen ‚Wissens‘ (über die Trainingsdaten hinaus) ein blinder Fleck: Sprachmodelle leiden unter einem Phänomen, das Programmierer:innen „Halluzinieren“ nennen3. Sie sind darauf programmiert, (fast) immer eine Antwort zu geben, die auf der Ebene von ‚sich nahe stehenden‘ Wortgruppen eine hinreichend hohe Wahrscheinlichkeit haben, um für die Nutzer:in (nachträglich) Sinn zu ergeben. ChatGPT ist daher konzeptionell eine Fake-Maschine zur Produktion von plausibel erscheinenden, aber nicht notwendigerweise faktenbasierten Inhalten und damit hervorragend geeignet für die Verbreitung von Mis- oder gar Desinformation.
Damit verstärkt sich ein Effekt, der bereits durch das algorithmische Ranking bei den sozialen Medien erkennbar wurde. Nicht-faktengebundene Inhalte können so weit selbstverstärkend im individuellen Nachrichtenstrom ‚nach oben‘ gespült werden, dass Meinungsbilder verzerrt werden. Und damit ist die zentrale These dieses Textes:
ChatGPT ermöglicht das (automatisierte und voraussetzungslose) Produzieren von post-faktischen Inhalten, die im Wechselspiel mit der algorithmischen Reichweitensteuerung sozialer Medien und den Ranking-Algorithmen der Suchmaschinen statistisches Gewicht erlangen. Die Rückkopplung der so generierten Inhalte sozialer Medien in den Trainingsdatensatz der nächsten Generation von Sprachmodellen ermöglicht sogar eine Dominanz synthetischer Inhalte im Netz.
‚Kannibalismus‘ und Zensur bei wachsendem Anteil KI-generierter Inhalte
Eine derartige Dominanz hat messbare Konsequenzen. Die Größe von Sprachmodellen nimmt zu und damit auch der Bedarf an Trainingsmaterial für das maschinelle Lernen. Immer mehr synthetische Inhalte werden zum Training herangezogen, denn je mehr Inhalte KIs wie ChatGPT oder Google Bard produzieren, desto häufiger werden sie ihre eigenen Inhalte in ihren Datensatz aufnehmen. Das geschieht beim sogenannten Datenschürfen, bei dem automatisierte Programme nahezu alles an Daten aufsaugen, was frei im Internet verfügbar ist. Google bedient sich zudem bei den eigenen Anwendungen wie Gmail, in Speicherdiensten wie Google Drive oder Google Docs.
Durch das Wiederverdauen selbst generierter Inhalte entsteht eine „selbstverzehrende“ Rückkopplungsschleife, die einer nachweisbaren Störung unterliegt, der sogenannten Model Autophagy Disorder (MAD)4: Die Fehler zum Beispiel von Bild-Generatoren verstärken sich rekursiv zu regelrechten Artefakten und sorgen für eine abnehmende Datenqualität. Siehe dazu die Abbildung künstlich erzeugter Gesichter bei deren Wiederverwendung als Trainingsmaterial in der nächsten Generation (t=3) bzw. in übernächster Generation (t=5), usw. Noch wesentlicher ist eine massiv schrumpfende Diversität der Inhalte im Netz bei zu geringer Beimischung neuer, nicht-synthetischer Inhalte. Ähnliches lässt sich bei der Text-Erzeugung durch ChatGPT beobachten.

Bereits im April 2023 (kurz nach Freischaltung des kostenfreien Schnittstelle zur Nutzung von ChatGPT) hat NewsGuard rund 50 Nachrichten- und Informationsseiten in sieben Sprachen identifiziert, die fast vollständig von KI-Sprachmodellen generiert werden.5 Diese Webseiten produzieren eine Vielzahl von rein synthetischen Artikeln zu verschiedenen Themen, darunter Politik, Gesundheit, Unterhaltung, Finanzen und Technologie. Damit scheinen sich die Befürchtungen von Medienwissenschaftler:innen zu bestätigen: Zur Erzeugung von Werbeeinnahmen und / oder zur Debattenbeeinflussung verbreiten algorithmisch generierte Nachrichtenseiten KI-generierte Inhalte von fiktiven Verfasser:innen. Den meisten Leser:innen stehen keine Möglichkeiten zur Verfügung, diese Artikel als synthetisch zu identifizieren.6
Von Produktrezensionen über Rezeptsammlungen bis hin zu Blogbeiträgen, Pressemitteilungen, Bildern und Videos – die menschliche Urheberschaft von Online-Texten ist auf dem besten Weg, von der Norm zur Ausnahme zu werden. Pessimistische Prognosen sagen bis zum Ende dieses Jahrzehnts einen Anteil von bis zu 90% KI-generierter Inhalte im Internet voraus.7 Schon jetzt tauchen diese KI-generierten Texte in den Ergebnislisten der Suchmaschinen auf. Eingreifen will Google erst bei „Inhalten mit dem Hauptzweck, das Ranking in den Suchergebnissen zu manipulieren“.8
Wie sollen wir mit der Datenexplosion umgehen, die diese KIs nun verursachen werden? Wie verändert sich eine Öffentlichkeit, die so unkompliziert mit Mis- und Desinformation geflutet werden kann? Bei steigendem Anteil können derartige synthetische Inhalte den ‚Nutzen‘ des Internet drastisch reduzieren: Wer kämpft sich durch einen (noch viel) größeren Berg an quasi-sinnloser Information – ohne Bezug zur Lebensrealität menschlicher Autor:innen? Lässt sich feststellen, ob ein Text, ein Bild, eine Audio- oder eine Videosequenz durch eine KI generiert bzw. gefälscht wurde? Schon bieten Software-Hersteller Werkzeuge zur Detektion von KI-generierten Inhalten an – selbstverständlich ebenfalls auf der Basis einer künstlich-intelligenten Mustererkennung. Menschlich verfasste Texte sollen sich über statistische Abweichungen von den Wahrscheinlichkeitsmustern der verwendeten Wortgruppierungen der KI-Sprachmodelle unterscheiden lassen. Dies sind jedoch statistische Differenzen, deren Erkennung im Einzelfall damit hochgradig fehleranfällig ist.
Im Falle einer Dominanz von synthetischen Inhalten wird die Mehrheit der Nutzer:innen von Kommunikationsplattformen nach automatisierter Löschung rufen, da ein ‚unbereinigter‘ Nachrichtenstrom für sie zu viel und zu schwer erkennbaren ‚Unsinn‘ enthält. Damit ergibt sich eine Lizenz zum (immanent politischen) Löschen bzw. zur Unsichtbarmachung von Inhalten im Netz. Den Architekt:innen der nun anzupassenden Social Media-Algorithmen und den Datenaufbereiter:innen für Training und Output der großen Sprachmodelle kommt dann eine nicht hinnehmbare Macht innerhalb der politischen Öffentlichkeit zu:
Eine KI-basierte Bewältigung des Problems synthetischer Inhalte im Netz ist ein politisches Desaster für die historische Entwicklung des Internet, welches vorgab, die Demokratisierung der Wissenszugänge und des Informationsaustauschs voranzutreiben.
Die Machtkonzentration auf ein kleines Oligopol ist umso größer, als die Privatisierung von Sprachtechnologien massiv voranschreitet. Als die Chef-Entwicklerin von ChatGPT Mira Murati 2018 bei OpenAI startete, war das Unternehmen noch als gemeinnütziges Forschungsinstitut konzipiert: Es ging darum, „sicherzustellen, dass künstliche allgemeine Intelligenz der ganzen Menschheit zugutekommt“. 2019 folgte, wie gewöhnlich bei angehenden Einhörnern, die als offene Entwickler:innen-Projekte gestartet sind, die Abkehr vom Non-Profit-Modell. Die mächtigsten KI-Unternehmen halten ihre Forschung unter Verschluss. Das soll verhindern, dass die Konkurrenz von der eigenen Arbeit profitiert. Der Wettlauf um immer umfangreichere Modelle hat schon jetzt dazu geführt, dass nur noch wenige Firmen im Rennen verbleiben werden – neben dem GPT-Entwickler Open AI und seiner Microsoft-Nähe sind das Google, Facebook, xAI (neue Firma von Elon Musk), Amazon und mit Einschränkung9 chinesische Anbieter wie Baidu. Kleinere, nichtkommerzielle Unternehmen und Universitäten spielen dann so gut wie keine Rolle mehr. Der ökonomische Hintergrund dieser drastisch ausgedünnten Forschungslandschaft: Das Training der Sprachmodelle ist eine Ressourcen-intensive Angelegenheit, welches eine massive Rechenleistung und damit einen beträchtlichen Energieaufwand erfordert. Ein einziger Trainingslauf für das derzeit größte Sprachmodell GPT-4 kostet aktuell 63 Millionen Dollar. 10
Auf der Überholspur ins Zeitalter von Deepfakes
Analog zur (Text-zu-)Texterzeugung per ChatGPT nutzen Programm wie Midjourney oder Stablediffusion einen ebenfalls auf maschinellem Lernen basierenden (Text-zu-)Bildgenerator, um aus einer textförmigen Bildbeschreibung synthetische Bilder zu erzeugen. Die so erstellten Fake-Bilder einer fiktiven Festnahme von Donald Trump und eines im Rapper-Style verfremdeten Papstes galten dem Feuilleton zu Anfang des Jahres weltweit als ikonische Zeugnisse einer ‚neuen Fake-Ära‘ des Internet. Dabei waren beide lediglich gut gemachte, aber harmlose Bildfälschungen. Andere Formen der sprachmodellbasierten Mis- und Desinformation sind von weit größerer Tragweite.
Auf der Code Conference 2016 äußerte sich Elon Musk wie folgt zu den Fähigkeiten seines Tesla-Autopiloten: „Ein Model S und Model X können zum jetzigen Zeitpunkt mit größerer Sicherheit autonom fahren als ein Mensch. Und das bereits jetzt.“11 Elon Musks Anwält:innen behaupteten nun im April 2023 zur Abwehr einer Schadensersatzklage vor Gericht, das Video des Konferenzbeitrags, in dem Musk diese juristische folgenreiche Behauptung aufstellte, sei ein Deepfake.12
Bereits ein Jahr zuvor argumentierten zwei Angeklagte, die wegen der Kapitolerstürmung im Januar 2021 vor Gericht standen, das Video, welches sie im Kapitol zeige, könne von einer Künstlichen Intelligenz erstellt oder manipuliert worden sein. Täuschung und vorgetäuschte Täuschung gab es schon immer. Diese Debatte hatten wir bereits bei der Popularisierung der Bildbearbeitungssoftware Photoshop. Neu ist, dass es keiner handwerklichen Fertigkeiten bedarf und die für alle zugängliche, quasi-instantane Manipulierbarkeit auch Video- und Audio-Sequenzen betrifft.
„Das Hauptproblem ist, dass wir nicht mehr wissen, was Wahrheit ist“ (Margaret Mitchell, ehemalige Google-Mitarbeiterin und jetzige Chefethikerin des KI-Startups Hugging Face).
„Das ist genau das, worüber wir uns Sorgen gemacht haben: Wenn wir in das Zeitalter der Deepfakes eintreten, kann jeder die Realität leugnen“, so Hany Farid, ein Experte für digitale Forensik und Professor an der University of California, Berkeley. „Das ist die klassische Lügendividende13.“ Eine skeptische Öffentlichkeit wird dazu gebracht, die Echtheit von echten Text-, Audio,- und Videodokumenten anzuzweifeln.
Angesichts der beachtlichen Geschwindigkeit, mit der ChatGPT neue Nutzer:innen gewinnt, bedeutet dies einen enormen zukünftigen Schub für das Postfaktische, dessen Hauptwirkungsweise nicht darin besteht, dass selbstkonsistente Parallelwelten von Falscherzählungen für sich ‚Wahrheit‘ im Sinne einer Faktizität reklamieren, sondern dass sie die Frage „Was ist wahr und was ist falsch?“ (zumindest in Teilen des öffentlichen Diskursraums) für unwichtig erklären.
Große Sprachmodelle sind geradezu das Ideal des Bullshitters, wie der Philosoph Harry Frankfurt, Autor von On Bullshit, den Begriff definierte. Bullshitter, so Frankfurt, sind schlimmer als Lügner. Ihnen ist es egal, ob etwas wahr oder falsch ist. Sie interessieren sich nur für die rhetorische Kraft einer Erzählung. Beide Aspekte, das Ignorieren der Frage nach wahr oder falsch, als auch deren aktive Dekonstruktion haben das Potential, Gewissheiten über das Funktionieren von Gesellschaft zu zerlegen. Selbstorganisiertes politisches Engagement von unten droht zu einem Blindflug entlang falscher Annahmen zu werden. Die darauf folgende Ernüchterung befördert den Rückzug ins Private – ein durchaus gewünschter und geförderter Aspekt14. Politisch profitieren können von einem hohen Anteil an Misinformation rechte Kräfte, denen an einer gesellschaftlichen Destabilisierung durch wachsende Polarisierung gelegen ist. Steve Bannon (ehemalige Berater von Donald Trump), bezeichnete die Medien immer wieder als Feind, den es niederzuringen gelte. Dazu müsse man „das [mediale] Feld mit Scheiße fluten“. Je stärker die Akzeptanz verbreiteter Information von ihrem Wahrheitsgehalt entkoppelt ist, desto leichter lässt sich dann auch manipulative Desinformation verbreiten. Falschnachrichten sind meist überraschend und erzeugen deutlich mehr Aufmerksamkeit. Bewusst adressierte Affekte wie Empörung, Angst und Hass erzeugen bei der Leser:in nachweislich mehr Aktivität und halten die Nutzer:innen damit länger in sozialen Netzwerken als etwa Freude, Zuversicht und Zuneigung. Dieses Muster wird von der algorithmischen Reichweitensteuerung sozialer Medien erkannt und rückkoppelnd als Trend verstärkt. Über diese statistische Gewichtsverzerrung bevorzugt rechter Beiträge innerhalb politischer Debatten ist z.B. auf Twitter eine deutliche Rechtsverschiebung zu verzeichnen – und das bereits weit vor der Übernahme durch Elon Musk und dessen Neuausrichtung des Algorithmus.15 Der Siegeszug des Trumpismus nach 2016 ist ein gut untersuchtes Beispiel derartig kontaminierter Diskursräume.
Bedenklicher Reduktionismus
Suchmaschinen wie Bing oder Google haben begonnen, ihre KI-Sprachmodelle GPT-4 bzw. PaLM zur zusammenfassenden Weiterverarbeitung gefundener Suchergebnisse zu implementieren. Damit wird die (per Ranking-Algorithmus vorsortierte, aber immerhin noch vorhandene) bisherige Auswahl von Suchergebnissen reduziert auf ein leicht konsumierbares Ergebnis auswählbaren Umfangs. Eine enorme Vereinfachung zugunsten einer beträchtlichen Zeitersparnis bei der Internetsuche, aber zulasten einer Vielfalt möglicher (kontroverser) Ergebnisse.
Wer erste Nutzungserfahrungen mit ChatGPT gesammelt hat, wird bei vielen Text-Antworten auf Wissensfragen zu kontroversen Themen eine vermeintliche Ausgewogenheit feststellen. Einer detailliert dargestellten Mehrheitsmeinung wird ein Zusatz angehängt, dass es dazu durchaus anderslautende Interpretationen gibt. Politische Widersprüche, die in den (sich widersprechenden) Suchergebnissen noch bestanden, werden nun mit einer durch das Sprachmodell vordefinierten Diversitätstiefe aufgelöst. Dadurch ergibt sich ein politisch bedenklicher Reduktionismus, der wohlgemerkt auf einem Sprachmodell(!) basiert – also nicht wissensbasiert ist, sondern mangels Verständnis von Begriffsbedeutungen rein statistisch bestimmt ist.
Diese ‚kritischen’ Anmerkungen werden zukünftig zur sogenannten Medienkompetenz gezählt werden und bedeutungslos (wie alles in der Welt der Sprachmodelle) verhallen. Wer klickt noch in schier endlosen Suchergebnislisten herum, wenn die Suche bei Google oder Bing das ‚Wichtigste‘ für uns zusammenfasst?16
Vergangenheit in die Zukunft projiziert
ChatGPT ist ein stochastischer Papagei, der (willkürlich) Sequenzen sprachlicher Formen zusammenfügt, die er in seinen umfangreichen Trainingsdaten beobachtet hat, und zwar auf der Grundlage probabilistischer Informationen darüber, wie sie kombiniert werden, aber ohne jeglichen Bezug zu deren Bedeutung. Ein solcher Papagei reproduziert und verstärkt dabei nicht nur den Bias von verzerrten Trainingsdaten, sondern auch hegemoniale Weltanschauungen dieser Trainingsdaten. Gesellschaftliche Verhältnisse aus der Vergangenheit der Trainingsdaten werden in die Zukunft verstetigt. Die den Sprachmodellen immanente Rekombination statistisch dominanter Wissenseinträge der Trainingsdaten wirkt die Verhältnisse konservierend und stabilisierend – ein sogenannter value lock, das Einrasten von Werten im Sinne einer politischen Stagnation droht.17
Die Bedingungen einer solchen Hegemonieverstärkung werden leider nur marginal gesellschaftlich (mit-)bestimmt. Das komplexe System aus Trainingsdatenaufbereitung, Parameterjustierung des Sprachmodells und nachträglicher Zensur des Outputs (allesamt unter der Kontrolle profitorientierter Privatunternehmen) bestimmen das Gewicht von neuen Wissenseinträgen. Damit liegt die hohe Hürde einer ausreichenden statistischen Relevanz emanzipatorischer Debattenbeiträge außerhalb einer demokratisch verfassten, gesellschaftlichen Mitbestimmung. Angesichts eines deutlichen politischen Drifts nach rechts maßgeblicher Technokrat:innen des KI-Geschäftsmodells (wie Sam Altman, Elon Musk, Peter Thiel, …) sind das keine hinnehmbaren Voraussetzungen für eine gesellschaftlich progressive Entwicklung.
Diversitätsverlust und Rechtsdrift
Die intrinsische Hegemonieverstärkung großer Sprachmodelle über ein selbstverstärkendes Wiederverdauen des eigenen Outputs als Input für das nächste Training des Modells bedeutet einen Verlust an Meinungsvielfalt (siehe Abbildung links+Mitte).
Zusätzlich führt die zuvor erwähnte Bevorzugung (in Reichweite und Verbreitungsgeschwindigkeit) verschwörerischer und (rechts-)populistischer Inhalte in den sozialen Medien zu einer politisch rechts gerichteten Verzerrung in den Trainingsdaten der nächsten Generation von Sprachmodellen. Dadurch erwarten wir in der Überlagerung beider Effekte einen rechtslastigen Diversitätsverlust (Abbildung rechts).
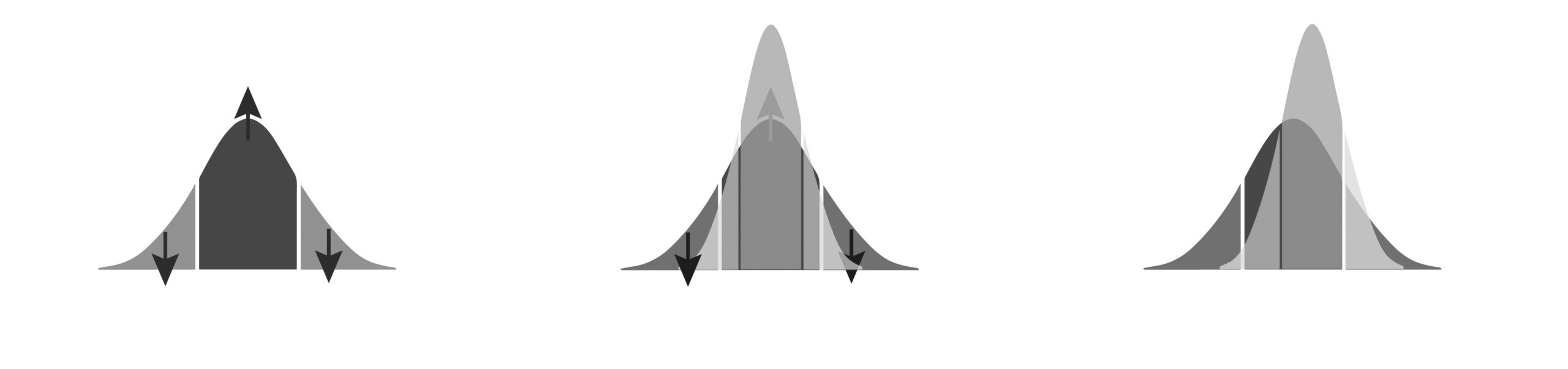
Eine solche Deformation öffentlicher Diskursräume über die Wechselwirkung großer Sprachmodelle mit den sozialen Medien zugunsten einer a) hegemonial-konservativen Meinungseinfalt und b) einer zentralen Machtposition eines Technologie-Oligopols, welches die Verzerrung algorithmisch codiert, muss aus der Sicht einer progressiven Position als Rückschritt und als politische Sackgasse zurückgewiesen werden. Die Unzulänglichkeit der sich neu ergebenden Informationsinfrastruktur bestehend aus großen Sprachmodellen + Social Media–Plattformen + Suchalgorithmen wird sich wohl kaum durch eine gesellschaftlich legitimierte, besser ausbalancierte Inhalte-Moderation abfedern lassen.
Ein emanzipatorischer Zugang zu einer grundlegenden Technologiekritik darf nicht auf der Ebene kosmetischer Korrekturen einer zahnlosen „Technikfolgenabschätzung“ verharren. Anstatt große Sprachmodelle unkritisch als unausweichlichen technologischen Fortschritt hinzunehmen, sollten wir die Frage aufwerfen, ob, und nicht wie, wir diese Technologien überhaupt gesellschaftlich akzeptieren sollten. Die langfristigen gesellschaftlichen Folgen dieser Modelle innerhalb einer dominanten KI-Empfehlungs- und Entscheidungs-Assistenz insbesondere für den Prozess der politischen Willensbildung, tauchen in einer nun allseits geforderten technischen Sicherheitsforschung von KI-Systemen als ‚schwer zu quantifizieren‘ gar nicht auf.18
Wir sollten unsere Haltung in Bezug auf die politische Schadwirkung KI-basierter Sprachmodelle ausrichten an unserer Haltung gegenüber KI-basierten, autonomen Waffensystemen: Warum sollte eine Gesellschaft einen derart rückwärts gewandten technologischen ‚Fortschritt‘ hinnehmen?
„Marx sagt, die Revolutionen sind die Lokomotive der Weltgeschichte. Aber vielleicht ist dem gänzlich anders. Vielleicht sind die Revolutionen der Griff des in diesem Zuge reisenden Menschengeschlechts nach der Notbremse.“19 (Walter Benjamin)
1https://nymag.com/intelligencer/article/ai-artificial-intelligence-chatbots-emily-m-bender.html
2Ein Computerprogramm, welches möglichst menschenähnlich kommuniziert.
3Die Psychologie spricht genauer von „Konfabulationen“.
4Alemohammad et al., Self-Consuming Generative Models Go MAD, 2023, https://arxiv.org/abs/2307.01850
5https://www.newsguardtech.com/de/special-reports/newsbots-vermehrt-ai-generierte-nachrichten-webseiten/
6https://www.theguardian.com/books/2023/sep/20/amazon-restricts-authors-from-self-publishing-more-than-three-books-a-day-after-ai-concerns
7https://www.youtube.com/watch?v=DgYCcdwGwrE
8https://developers.google.com/search/blog/2023/02/google-search-and-ai-content?hl=de
9Die weitreichende Zensur von Trainingsdaten und Output chinesischer Sprachmodelle stellen wegen der damit verengten Datenbasis ein großen Wettbewerbsnachteil dar. Eine weitere Hürde ist die Hardware. US-Regulierungen verhindern den Export der neuesten KI-Chips von Nvidia u.a. nach China. Diese Chips sind (derzeit) entscheidend für die Entwicklung und Verbesserung von KI-Modellen.
10https://the-decoder.de/leaks-zeigen-gpt-4-architektur-datensaetze-kosten-und-mehr/
11https://www.vox.com/2016/6/6/11840936/elon-musk-tesla-spacex-mars-full-video-code
12https://www.theguardian.com/technology/2023/apr/27/elon-musks-statements-could-be-deepfakes-tesla-defence-lawyers-tell-court
13Die „Lügendividende“ ist ein Begriff, den Robert Chesney und Danielle Citron 2018 in einer Veröffentlichung Deep Fakes: A Looming Challenge for Privacy, Democracy, and National Security, prägten. Darin beschrieben sie die Herausforderungen, die Deepfakes für die Privatsphäre, die Demokratie und die nationale Sicherheit darstellen. Der zentrale Gedanke darin ist, dass die Allgemeinheit sich bewusst wird, wie einfach es ist, Audio- und Videomaterial zu fälschen, und dass diese Skepsis als Waffe einsetzbar ist: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3213954
14Beispielhaft steht hierfür die Politik von Vladislav Surkov, Spindoktor Putins. https://www.nytimes.com/2014/12/12/opinion/russias-ideology-there-is-no-truth.html
15Aral, S. (2018): The spread of true and false news, Science 359,1146-1151(2018), https://www.science.org/doi/10.1126/science.aap9559
16Amazons Spracherkennungs- und -steuerungssoftware Alexa befördert ebenfalls diesen Reduktionismus, da sich niemand von Alexa eine längere Liste von Sucheinträgen vorlesen lassen möchte. Wegen der oft wenig hilfreichen Sprachausgabe eines weit oben gelisteten Treffers ist die Googlesuche über Alexa allerdings weit weniger beliebt.
17Bender et al: On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? (2021) https://dl.acm.org/doi/pdf/10.1145/3442188.3445922
18Siehe dazu: Nudging – die politische Dimension psychotechnologischer Assistenz, DISS-Journal#43 (2022) http://www.diss-duisburg.de/2022/08/nudging-die-politische-dimension-psychotechnologischer-assistenz/
19Walter Benjamin: MS 1100. In: Ders.: Gesammelte Schriften. I, hg. v. R. Tiedemann und H. Schweppenhäuser, Frankfurt am Main: Suhrkamp 1974, 1232.
von Calpulcu
